library(tidyverse)
library(rstan)
rstan_options(auto_write = TRUE) # save compiled STAN object
library(shinystan) # graphical exploration
library(posterior) # for summarizing draws
library(bayesplot) # for plotting
theme_set(theme_classic() +
theme(panel.grid.major.y = element_line(color = "grey92")))
Although many statistical models can be fitted using Bayesian or frequentist methods, some models are more naturally used in the Bayesian framework. One class of such models is the family of hierarchical models. Consider situations when the data contain some clusters, such as multiple data points in each of many participants, multiple participants in each of several treatment conditions, etc. While it is possible to run \(J\) Bayesian analyses for the \(J\) subsets of the data, it is usually more efficient to pool the data together, such that cluster \(j\) has some parameters \(\theta_j\), and these \(J\) \(\theta\) values themselves come from a common distribution. This is the same idea as multilevel modeling.
In this note, you will see two examples, one from the textbook with a hierarchical Bernoulli/binomial model, and another from a classic data set with eight schools, modelled by a hierarchical normal model.
Hierarchical Bernoulli/Binomial
Previously, we have seen the Bernoulli model for \(N\) outcomes, such as multiple coin flips from the same coin: \[y_i \sim \text{Bern}(\theta_i), \text{for }i = 1, \ldots, N\] We assumed exchangeability as the flips are from the same coin.
Alternative Parameterization of Beta
Previously we have used the Beta(a, b) prior for a Bernoulli outcome, such that \[P(\theta \mid a, b) \propto \theta^{a - 1} (1 - \theta)^{b - 1}.\] However, in hierarchical models to be discussed later, it is beneficial to consider another way to express the Beta distribution, in terms of the prior mean, \(\mu = a / (a + b)\), \(\mu \in [0, 1]\), and the concentration, \(\kappa = a + b\), \(\kappa \in [0, \infty)\). So instead of the above formula, we can write \[P(\theta \mid \mu, \kappa) \propto \theta^{\mu \kappa - 1} (1 - \theta)^{(1 - \mu) \kappa - 1}.\] The two expressions represent exactly the same distribution, but just in terms of parameters of different meanings. Therefore, they are referred to as different parameterization of the Beta distribution.
Multiple Bernoulli = Binomial
With \(N\) exchangeable Bernoulli observations, an equivalent but more efficient way to code the model is to use the binomial distribution. Let \(z = \sum_{i = 1}^N y_i\), then \[z \sim \mathrm{Bin}(N, \theta)\]
Multiple Binomial Observations
Now, consider the situation with multiple coins, perhaps each coin with some noticeable differences, as discussed in chapter 9.2 of the textbook. If we have \(J\) = 3 coins, and \(N_j\) flips for the \(j\)th coin. If we believe that the coins all have the same bias, then we could consider the model \[z_j \sim \mathrm{Bin}(N_j, \theta),\] which still contains only one parameter, \(\theta\). However, if we have reason to believe that the coins have different biases, then we should have \[z_j \sim \mathrm{Bin}(N_j, \theta_{\color{red}{j}}),\] with parameters \(\theta_1, \ldots, \theta_j\).
We can assign priors to each individual \(\theta_j\). However, if our prior belief is such that there’s something common among the different coins, say they’re from the same factory, so that they come from the same distribution, we can have common parameters for the prior distributions of the \(\theta\)s: \[\theta_j \sim \mathrm{Beta2}(\mu, \kappa),\] note I use Beta2 to denote the mean parameterization. Here, we express the prior belief that the mean bias of the different coins is \(\mu\), and how each coin is different from the mean depends on \(\kappa\). Now, \(\mu\) and \(\kappa\) are hyperparameters. We can assign some fixed values to \(\mu\) and \(\kappa\), as if we know what the average bias is. However, the power of the hierarchical model is that we can put priors (or hyper priors) on \(\mu\) and \(\kappa\), and obtain posterior distributions of them, based on what the data say.
What priors to use for \(\mu\) and \(\kappa\)? \(\mu\) is relatively easy because it is the mean bias; if we put a Beta prior for bias, we can again use a Beta prior for the mean bias. \(\kappa\) is more challenging. A larger \(\kappa\) means that the biases of the coins are more similar to each other. We can perform a prior predictive check to see what the data look like. As a starting point, chapter 9 of the textbook suggested using Gamma(0.01, 0.01). So the full model in our case, with a weak Beta(1.5, 1.5) prior on \(\mu\), is
Model: \[ \begin{aligned} z_j & \sim \mathrm{Bin}(N_j, \theta_j) \\ \theta_j & \sim \mathrm{Beta2}(\mu, \kappa) \end{aligned} \] Prior: \[ \begin{aligned} \mu & \sim \mathrm{Beta}(1.5, 1.5) \\ \kappa & \sim \mathrm{Gamma}(0.01, 0.01) \end{aligned} \]
Therapeutic Touch Example
See the description of the research problem from chapter 9.2.4 of the textbook.
# Data file from https://github.com/boboppie/kruschke-doing_bayesian_data_analysis/blob/master/2e/TherapeuticTouchData.csv
tt_dat <- read.csv("data_files/TherapeuticTouchData.csv")
# Get aggregated data by summing the counts
tt_agg <- tt_dat %>%
group_by(s) %>%
summarise(y = sum(y), # total number of correct
n = n())
# Plot proportion correct distribution
p1 <- ggplot(tt_agg, aes(x = y / n)) +
geom_histogram(binwidth = .1) +
labs(x = "Proportion Correct")

STAN Code
data {
int<lower=0> J; // number of clusters (e.g., studies, persons)
int y[J]; // number of "1"s in each cluster
int N[J]; // sample size for each cluster
}
parameters {
vector<lower=0, upper=1>[J] theta; // cluster-specific probabilities
real<lower=0, upper=1> mu; // overall mean probability
real<lower=0> kappa; // overall concentration
}
model {
y ~ binomial(N, theta); // each observation is binomial
theta ~ beta_proportion(mu, kappa); // prior; Beta2 dist
mu ~ beta(1.5, 1.5); // weak prior
kappa ~ gamma(.01, .01); // prior recommended by Kruschke
}Prior predictive
You can use Stan to sample the prior by commenting out the model line; here I show how to do it in R:
set.seed(1706)
plist <- vector("list", 12L)
plist[[1]] <- p1 +
labs(x = "Observed data") +
theme(axis.title.x = element_text(color = "red"))
num_subjects <- 28
for (s in 1:11) {
# Get prior values of mu and kappa
mu_s <- rbeta(1, shape1 = 1.5, shape2 = 1.5)
kappa_s <- rgamma(1, shape = 0.01, rate = 0.01)
# Generate theta
theta <- rbeta(num_subjects,
shape1 = mu_s * kappa_s, shape2 = (1 - mu_s) * kappa_s)
# Generate data
new_y <- rbinom(num_subjects, size = tt_agg$n, prob = theta)
plist[[s + 1]] <-
p1 %+% mutate(tt_agg, y = new_y) +
labs(x = paste("Simulated data", s)) +
theme(axis.title.x = element_text(color = "black"))
}
gridExtra::grid.arrange(grobs = plist, nrow = 3)
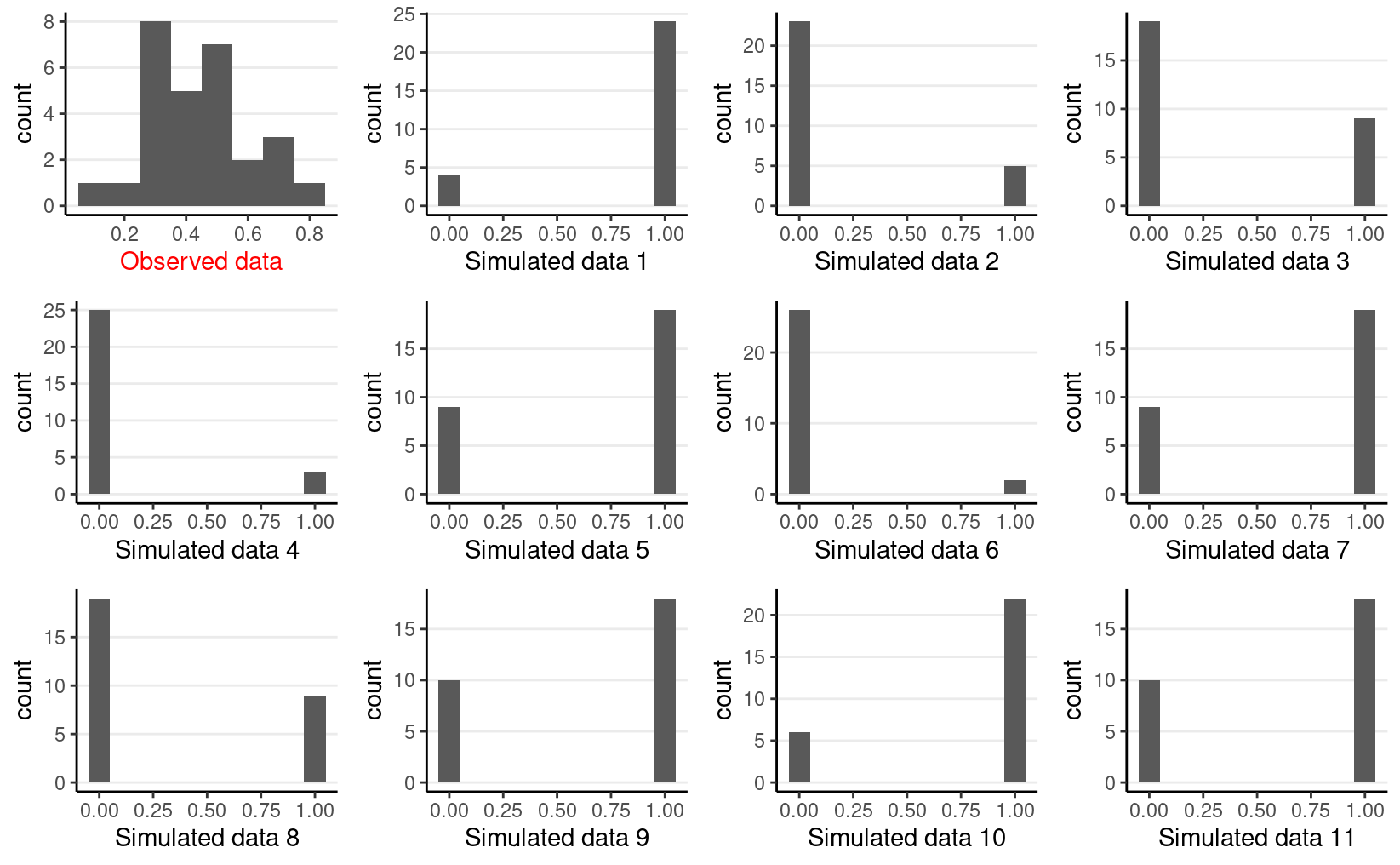
The prior on \(\kappa\) is actually not very realistic because it tends to push the bias to either 0 or 1. Using something like Gamma(0.1, 0.1) or Gamma(2, 0.01) may be a bit more reasonable (you can try it out yourself).
Calling rstan
tt_fit <- stan(
file = here("stan", "hierarchical_bin.stan"),
data = list(J = nrow(tt_agg),
y = tt_agg$y,
N = tt_agg$n),
seed = 1716, # for reproducibility
chains = 4,
iter = 4000, # default gives warning saying iter needs to be higher
# may need higher adapt_delta (default = .8) for hierarchical models
control = list(adapt_delta = 0.8)
)
You can explore the convergence and posterior distributions using the
shinystan package
launch_shinystan(tt_fit)
Table of coefficients
tt_fit %>%
# Convert to `draws` object to work with the `posterior` package
as_draws() %>%
# Get summary
summarize_draws() %>%
# Use `knitr::kable()` for tabulation
knitr::kable(digits = 2)
| variable | mean | median | sd | mad | q5 | q95 | rhat | ess_bulk | ess_tail |
|---|---|---|---|---|---|---|---|---|---|
| theta[1] | 0.37 | 0.38 | 0.08 | 0.08 | 0.22 | 0.49 | 1.00 | 2053.33 | 3524.75 |
| theta[2] | 0.39 | 0.40 | 0.08 | 0.07 | 0.25 | 0.51 | 1.00 | 2511.75 | 3398.59 |
| theta[3] | 0.41 | 0.41 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4815.11 | 4070.49 |
| theta[4] | 0.41 | 0.42 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4101.83 | 4049.36 |
| theta[5] | 0.41 | 0.41 | 0.08 | 0.07 | 0.28 | 0.54 | 1.00 | 4772.51 | 3885.97 |
| theta[6] | 0.41 | 0.41 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4047.04 | 3824.50 |
| theta[7] | 0.41 | 0.41 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4640.84 | 4110.38 |
| theta[8] | 0.41 | 0.42 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 5153.56 | 3501.47 |
| theta[9] | 0.41 | 0.42 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4419.30 | 3629.47 |
| theta[10] | 0.41 | 0.42 | 0.08 | 0.07 | 0.28 | 0.53 | 1.00 | 4456.35 | 4172.13 |
| theta[11] | 0.43 | 0.43 | 0.08 | 0.07 | 0.31 | 0.56 | 1.00 | 5807.17 | 4867.03 |
| theta[12] | 0.43 | 0.43 | 0.08 | 0.07 | 0.31 | 0.56 | 1.00 | 6574.03 | 4769.95 |
| theta[13] | 0.43 | 0.43 | 0.07 | 0.07 | 0.31 | 0.55 | 1.00 | 5961.52 | 5136.70 |
| theta[14] | 0.43 | 0.43 | 0.08 | 0.07 | 0.31 | 0.56 | 1.00 | 6730.63 | 4665.01 |
| theta[15] | 0.43 | 0.43 | 0.07 | 0.07 | 0.31 | 0.56 | 1.00 | 6650.31 | 4776.49 |
| theta[16] | 0.45 | 0.45 | 0.08 | 0.07 | 0.33 | 0.58 | 1.00 | 5540.38 | 4309.31 |
| theta[17] | 0.45 | 0.45 | 0.08 | 0.07 | 0.33 | 0.58 | 1.00 | 5923.26 | 4321.04 |
| theta[18] | 0.45 | 0.45 | 0.08 | 0.07 | 0.33 | 0.59 | 1.00 | 5847.91 | 4571.55 |
| theta[19] | 0.45 | 0.45 | 0.08 | 0.07 | 0.33 | 0.58 | 1.00 | 6091.28 | 4497.21 |
| theta[20] | 0.45 | 0.45 | 0.08 | 0.07 | 0.34 | 0.58 | 1.00 | 5986.57 | 5008.05 |
| theta[21] | 0.45 | 0.45 | 0.08 | 0.07 | 0.34 | 0.58 | 1.00 | 5802.48 | 4252.67 |
| theta[22] | 0.45 | 0.45 | 0.08 | 0.07 | 0.33 | 0.58 | 1.00 | 6348.07 | 4875.46 |
| theta[23] | 0.47 | 0.47 | 0.08 | 0.07 | 0.35 | 0.62 | 1.00 | 4740.90 | 3684.04 |
| theta[24] | 0.47 | 0.47 | 0.08 | 0.07 | 0.35 | 0.61 | 1.00 | 4619.95 | 3751.58 |
| theta[25] | 0.50 | 0.49 | 0.08 | 0.08 | 0.38 | 0.64 | 1.00 | 3260.56 | 4164.74 |
| theta[26] | 0.50 | 0.49 | 0.08 | 0.08 | 0.37 | 0.64 | 1.00 | 3150.89 | 3983.83 |
| theta[27] | 0.50 | 0.49 | 0.08 | 0.08 | 0.37 | 0.64 | 1.00 | 3107.08 | 4280.18 |
| theta[28] | 0.52 | 0.51 | 0.09 | 0.08 | 0.39 | 0.68 | 1.00 | 2300.07 | 3538.60 |
| mu | 0.44 | 0.44 | 0.03 | 0.03 | 0.39 | 0.50 | 1.00 | 1982.77 | 3741.91 |
| kappa | 64.85 | 42.77 | 65.48 | 33.83 | 12.37 | 189.87 | 1.01 | 614.23 | 1036.57 |
| lp__ | -198.32 | -198.72 | 10.33 | 10.87 | -214.29 | -180.15 | 1.01 | 550.59 | 935.98 |
Derived coefficients
One nice thing about MCMC is that it is straightforward to obtain posterior distributions that are functions of the parameters. For example, even though we only sampled from the posteriors of the \(\theta\)s, we can ask questions like whether there is evidence for a nonzero difference in \(\theta\) between person 1 and person 28.
as_draws_df(tt_fit) %>%
mutate_variables(
theta1_minus14 = `theta[1]` - `theta[14]`,
theta1_minus28 = `theta[1]` - `theta[28]`,
theta14_minus28 = `theta[14]` - `theta[28]`
) %>%
subset(variable = c("theta1_minus14", "theta1_minus28",
"theta14_minus28")) %>%
summarise_draws()
#> # A tibble: 3 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 theta1_mi… -0.0646 -0.0550 0.105 0.0963 -0.251 0.0883 1.00 4669.
#> 2 theta1_mi… -0.148 -0.126 0.133 0.123 -0.398 0.0280 1.00 1532.
#> 3 theta14_m… -0.0836 -0.0697 0.112 0.103 -0.289 0.0760 1.00 3427.
#> # … with 1 more variable: ess_tail <dbl>Conclusion
As 0.5 is included in the 95% CI of \(\theta\) for all participants, there is insufficient evidence that people can sense “therapeutic touch.”
Shrinkage
mcmc_intervals(tt_fit,
# plot only parameters matching "theta"
regex_pars = "theta") +
geom_point(
data = tibble(
parameter = paste0("theta[", 1:28, "]"),
x = tt_agg$y / tt_agg$n
),
aes(x = x, y = parameter),
col = "red"
) +
xlim(0, 1)

As can be seen, the posterior distributions are closer to the center than the data (in red). This pooling is a result of the belief that the participants have something in common.
Multiple Comparisons?
Another benefit of a Bayesian hierarchical model is that you don’t need to worry about multiple comparisons. There are multiple angles on why this is the case, but the basic answer is that the use of common prior distributions builds in the prior belief that the clusters/groups are likely to be equal. See discussion here and here.
Hierarchical Normal Model
Eight Schools Example
This is a classic data set first analyzed by Rubin
(1981). It is also the example used in the RStan
Getting Started page. The data contains the effect of coaching from
randomized experiments in eight schools. The numbers shown (labelled as
y) are the mean difference (i.e., effect size) in
performance between the treatment group and the control group on SAT-V
scores.
In the above data, some numbers are positive, and some are negative.
Because the sample sizes are different, the data also contained the
standard errors (labelled as sigma) of the effect sizes.
Generally speaking, a larger sample size corresponds to a smaller
standard error. The research question is
- What is the average treatment effect of coaching?
- Are the treatment effects similar across schools?
Model
Model: \[ \begin{aligned} d_j & \sim N(\theta_j, s_j) \\ \theta_j & \sim N(\mu, \tau) \end{aligned} \] Prior: \[ \begin{aligned} \mu & \sim N(0, 100) \\ \tau & \sim t^+_4(0, 100) \end{aligned} \]
Given the SAT score range, it is unlikely that a coaching program will improve scores by 100 or so, so we use a prior of \(\mu \sim N(0, 100)\) and \(\tau \sim t^+_4(0, 100)\).
Note: The model above is the same as one used in a random-effect meta-analysis. See this paper for an introduction.
Non-Centered Parameterization
The hierarchical model is known to create issues in MCMC sampling, such that the posterior draws tend to be highly correlated even with more advanced techniques like HMC. One way to alleviate that is to reparameterize the model using what is called the non-centered parameterization. The basic idea is that, instead of treating the \(\theta\)s as parameters, one uses the standardized deviation from the mean to be parameters. You can think about it as converting the \(\theta\)s into \(z\) scores, and then sample the \(z\) scores instead of the original \(\theta\)s.
Model: \[ \begin{aligned} d_j & \sim N(\theta_j, s_j) \\ \theta_j & = \mu + \tau \eta_j \\ \eta_j & \sim N(0, 1) \end{aligned} \]
data {
int<lower=0> J; // number of schools
real y[J]; // estimated treatment effects
real<lower=0> sigma[J]; // s.e. of effect estimates
}
parameters {
real mu; // overall mean
real<lower=0> tau; // between-school SD
vector[J] eta; // standardized deviation (z score)
}
transformed parameters {
vector[J] theta;
theta = mu + tau * eta; // non-centered parameterization
}
model {
eta ~ std_normal(); // same as eta ~ normal(0, 1);
y ~ normal(theta, sigma);
// priors
mu ~ normal(0, 100);
tau ~ student_t(4, 0, 100);
}Treatment effect estimates of individual schools (\(\theta\)), average treatment effect (\(\mu\)), and treatment effect heterogeneity (\(\tau\)).
#> Inference for Stan model: hierarchical_norm.
#> 4 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=4000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
#> theta[1] 11.40 0.14 8.23 -1.77 5.94 10.22 15.41 31.58 3572 1
#> theta[2] 7.96 0.09 6.31 -4.29 3.97 7.97 11.87 20.68 5296 1
#> theta[3] 6.18 0.12 7.75 -11.16 2.14 6.57 10.94 20.45 4147 1
#> theta[4] 7.69 0.09 6.43 -4.91 3.69 7.66 11.66 20.83 5536 1
#> theta[5] 5.15 0.10 6.27 -8.74 1.38 5.65 9.44 16.10 3929 1
#> theta[6] 6.04 0.10 6.73 -9.24 2.29 6.37 10.33 18.24 4413 1
#> theta[7] 10.36 0.10 6.63 -1.44 5.89 9.81 14.15 25.47 4439 1
#> theta[8] 8.32 0.12 7.47 -6.83 4.05 8.08 12.53 24.24 3823 1
#> mu 7.79 0.13 5.11 -2.20 4.69 7.89 11.01 17.54 1605 1
#> tau 6.28 0.14 5.32 0.23 2.38 5.00 8.75 19.55 1436 1
#>
#> Samples were drawn using NUTS(diag_e) at Thu Apr 28 11:40:14 2022.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).On average, based on the 95% CI, coaching seemed to improve SAT-V by -2.2 to 17.54 points. There was substantial heterogeneity across schools.
We can also get the probability that the treatment effect was > 0:
Here are the individual-school treatment effects:
mcmc_areas(fit, regex_pars = "theta")
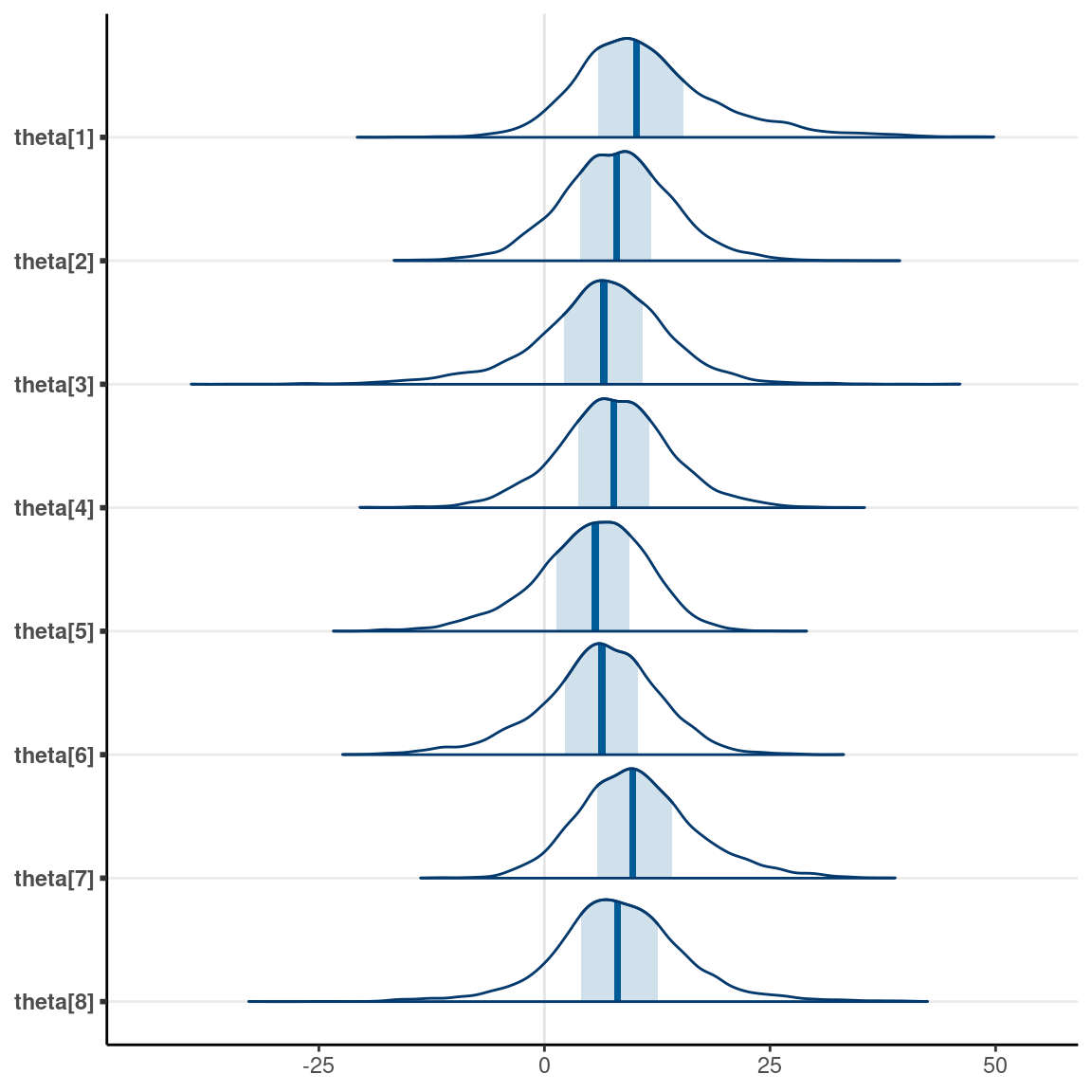
Prediction Interval
Posterior distribution of the true effect size of a new study, \(\tilde \theta\)
# Prediction Interval (can also be done in Stan)
extract(fit, pars = c("mu", "tau")) %>%
as_draws_array() %>%
mutate_variables(theta_tilde = rnorm(4000, mean = mu, sd = tau)) %>%
summarise_draws()
#> # A tibble: 3 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 mu 7.79 7.89 5.11 4.68 -0.356 15.9 1.00 4075.
#> 2 tau 6.28 5.00 5.32 4.45 0.463 16.5 1.00 4033.
#> 3 theta_tilde 7.87 7.84 9.79 7.13 -6.44 22.8 1.00 3816.
#> # … with 1 more variable: ess_tail <dbl>The posterior interval for \(\tilde \theta\) indicates a range that the treatment effect for a new study can be.
Last updated
#> [1] "March 10, 2022"