
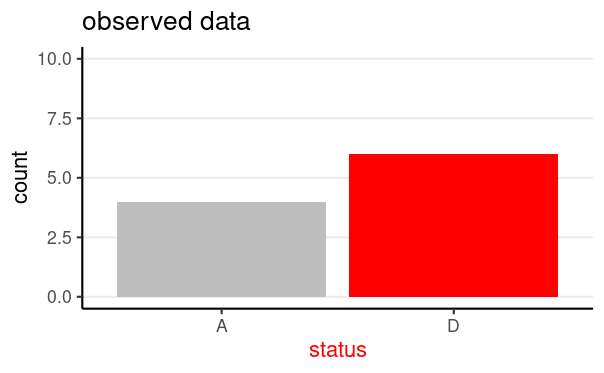
Let's go through the Bayesian crank
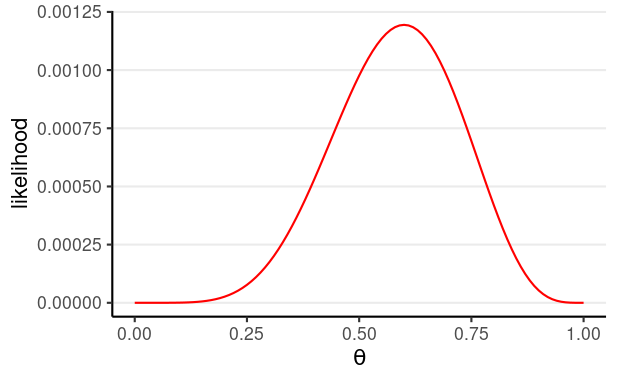
| theta | likelihood |
|---|---|
| 0.0 | 0.00000 |
| 0.1 | 0.00000 |
| 0.2 | 0.00003 |
| 0.3 | 0.00018 |
| 0.4 | 0.00053 |
| 0.5 | 0.00098 |
| 0.6 | 0.00119 |
| 0.7 | 0.00095 |
| 0.8 | 0.00042 |
| 0.9 | 0.00005 |
| 1.0 | 0.00000 |
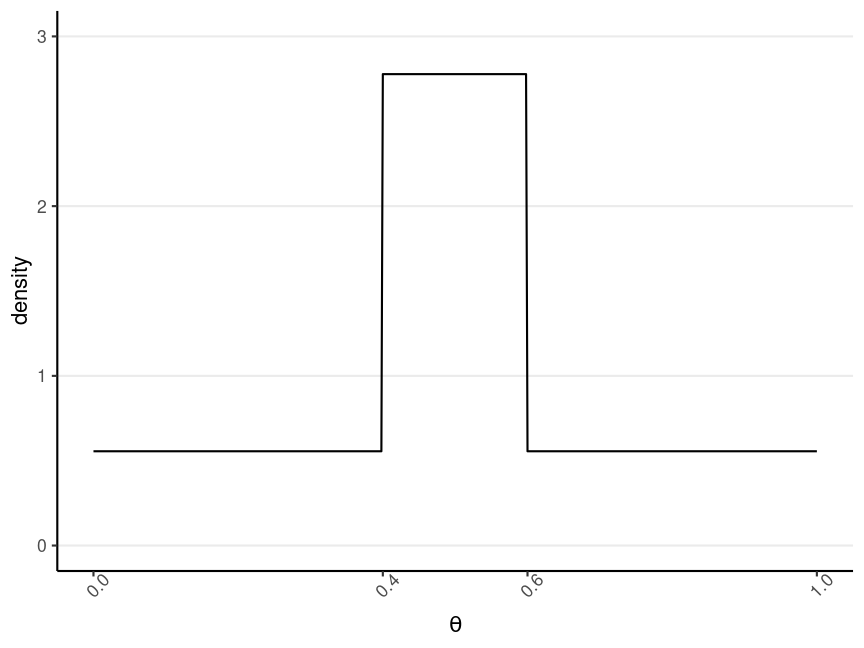
One Possible Option
Prior belief: is most likely to be in the range , and is 5 times more likely than any values outside of that range"
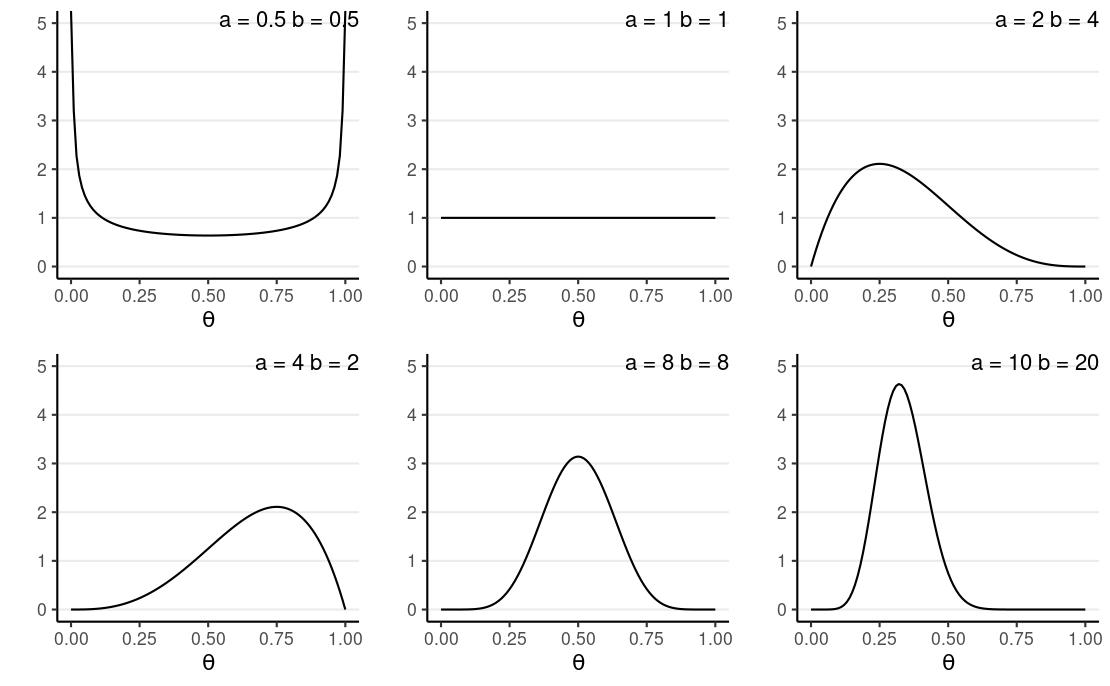
Two hyperparameters, and :
- = number of prior 'successes' (e.g., "D")
- = number of prior 'failures'
Back to the Example
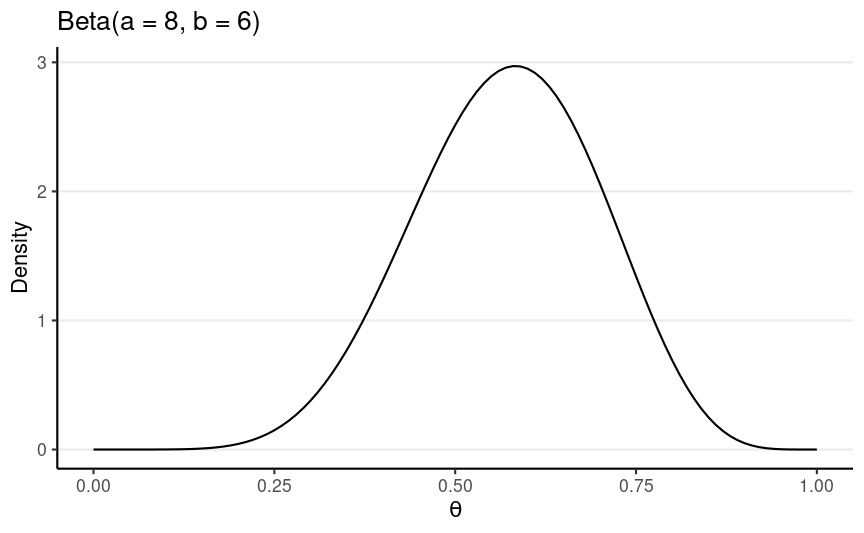
= 10, = 6
Prior: Do you believe that the fatality rate of AIDS is 100%? or 0%?
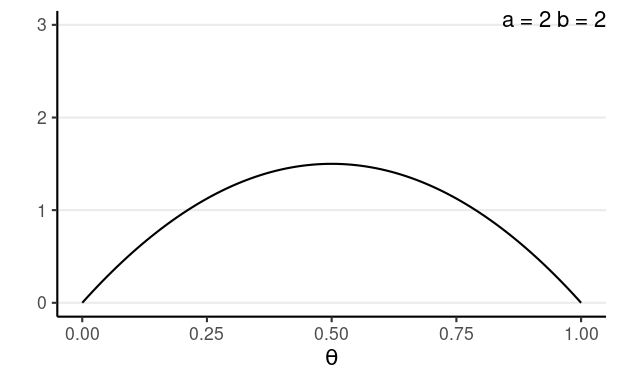
- Let's use , prior mean = 0.5, so = 2 and = 2
Use the Full Data
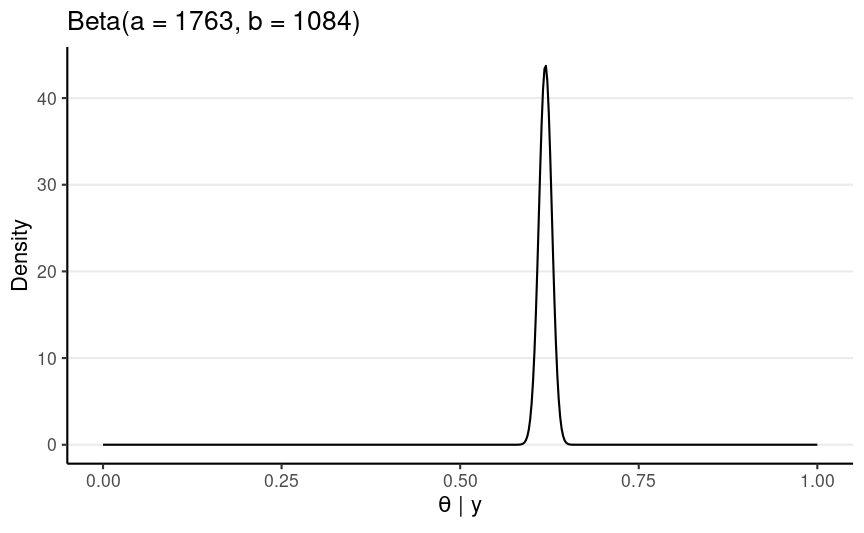
1082 A, 1761 D = 2843, = 1761
Posterior: Beta(1763, 1084)
Using bayesplot
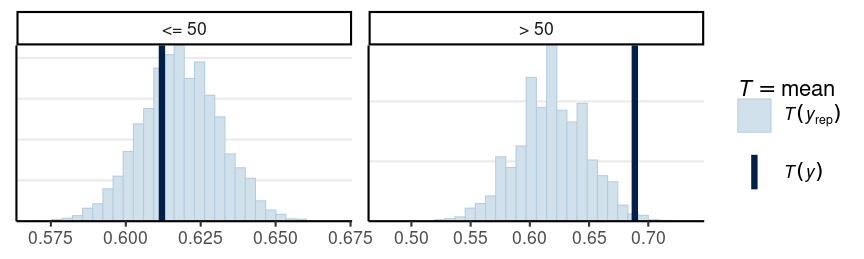
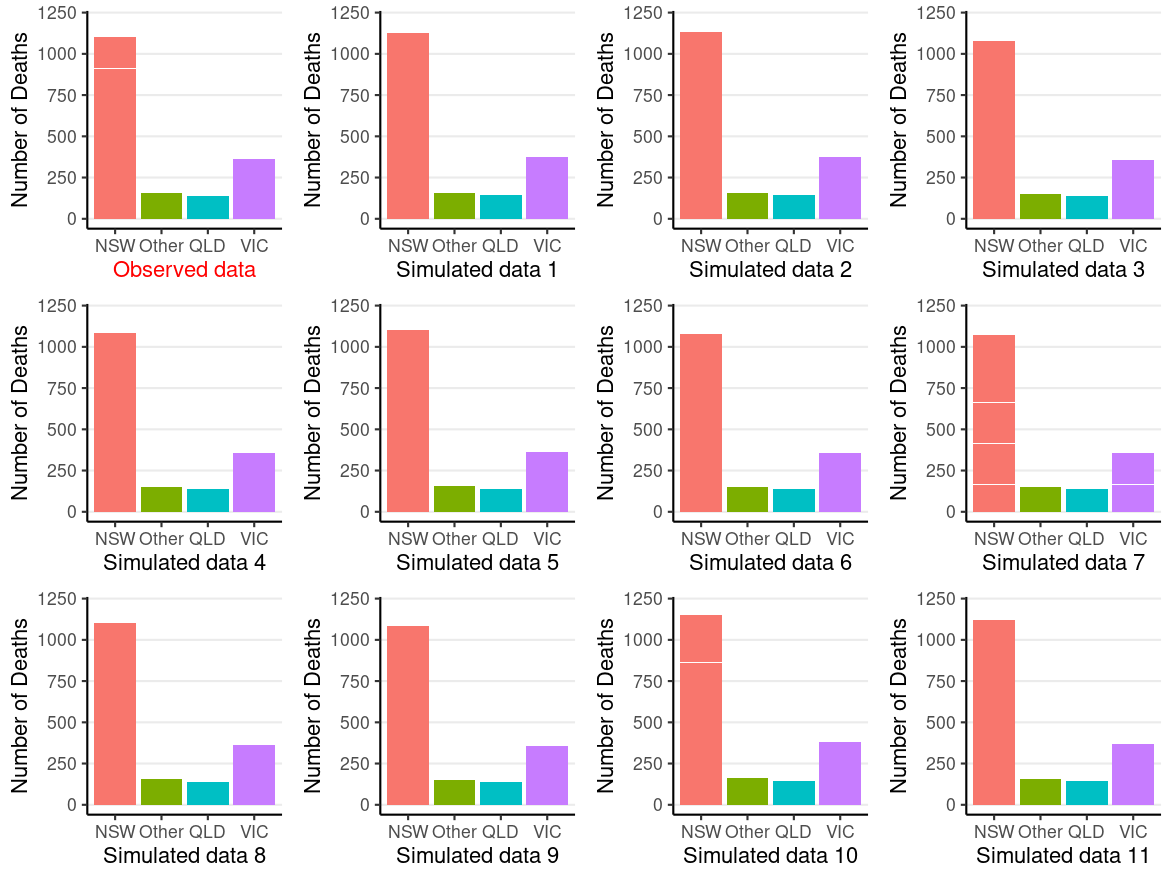
Darker line = observed proportion of "D"; histogram = simulated plausible statistics based on the model and the posterior
The model with one-parameter, which assumes exchangeability, does not fit those age 50+
- May need more than one
# Create an age group indicatorage50 <- factor(Aids2$age > 50, labels = c("<= 50", "> 50"))# Draw posterior samples of thetapost_sample <- rbeta(1e4, 1807, 1116)# Initialize an S by N matrix to store the simulated datay_tilde <- matrix(NA, nrow = length(post_sample), ncol = length(Aids2$status))for (s in seq_along(post_sample)) { theta_s <- post_sample[s] status_new <- sample(c("D", "A"), nrow(Aids2), replace = TRUE, prob = c(theta_s, 1 - theta_s) ) y_tilde[s,] <- as.numeric(status_new == "D")}bayesplot::ppc_stat_grouped( as.numeric(Aids2$status == "D"), yrep = y_tilde, group = age50)